
Table of Contents
Crawled Currently Not Indexed Error: What It Is And How To Solve It
The coverage report of Google Search Console is an extremely useful service that lets us see the indexing status of our web pages. Once you create a web page or a new blog post and submit it on Google search console, Google indexes it within a day or two. However, there are those frustrating times when you see the “crawled currently not indexed” error when you inspect the URL of your new web page on Google Search Console. There can be countless technical reasons behind this error. However, we can tell you from our experience that the crawled, currently not indexed, is most likely a content quality issue. Let’s delve deeper.
A Little Background
When you go to Google Search Console, you’ll see that there is an input field at the top. That’s the URL inspection field. We use this field to know the indexing status of a webpage and to submit newly created web pages to Google for faster indexing.
Now normally Google takes just 24 to 72 hours to index a page once you submit. After that, if you inspect the URL of your new webpage, the Search Console will show a message stating that the page has been successfully crawled and indexed. In short, it is now on Google.
For example, if we inspect our homepage URL, Google will return a result like this-
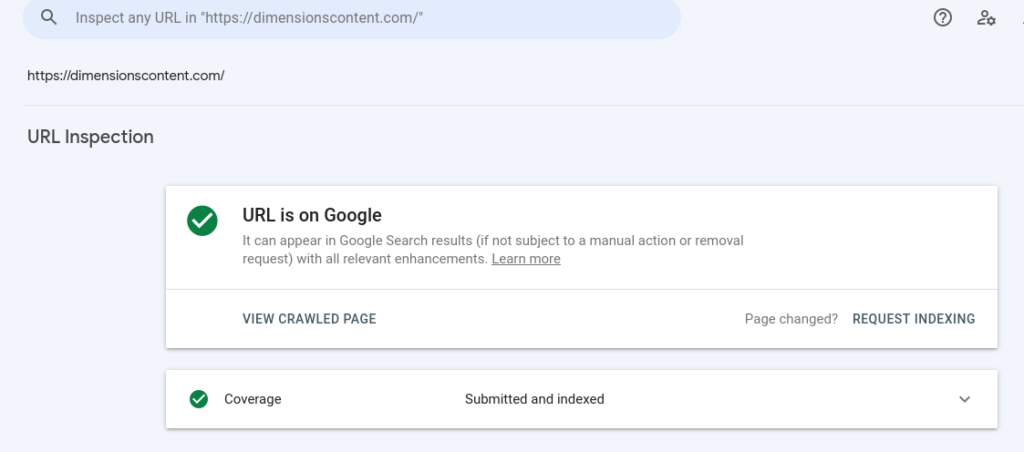
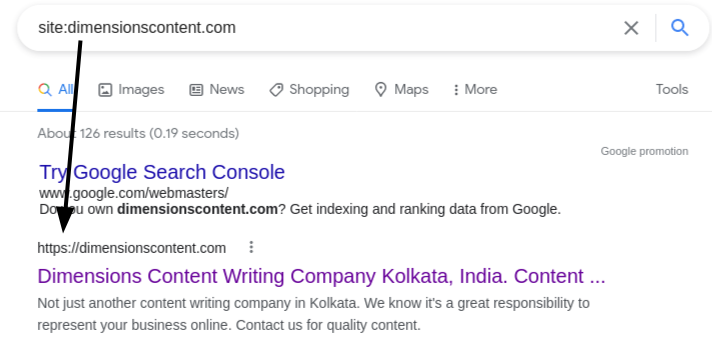
There is another simple way of examining whether your webpage is indexed or not. Go to Google Search and type “site:your-url.” For example if we want to see whether our homepage is indexed or not, we will type “site:dimensionscontent.com” (without quotation). If the page is indexed, Google will return a result like this-
Your First Task In Case of Crawled Currently Not Indexed Issue
If you see the ‘crawled currently not indexed’ message when you inspect an URL, the first thing that you need to do is to rule out any false positive. Head over to Google search and type ‘site:your-affected-url.’ If you don’t see that webpage on the search results page, then that webpage is indeed not indexed.
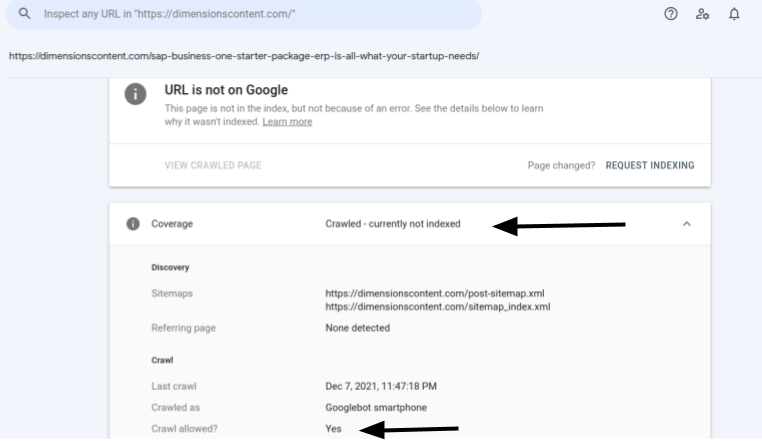
For example, we have an affected webpage- http://dimensionscontent.com/sap-business-one-starter-package-erp-is-all-what-your-startup-needs/ which is crawled by Google bots but not indexed. If we go to Google Search and type ‘site:http://dimensionscontent.com/sap-business-one-starter-package-erp-is-all-what-your-startup-needs/’ we see a result like this:
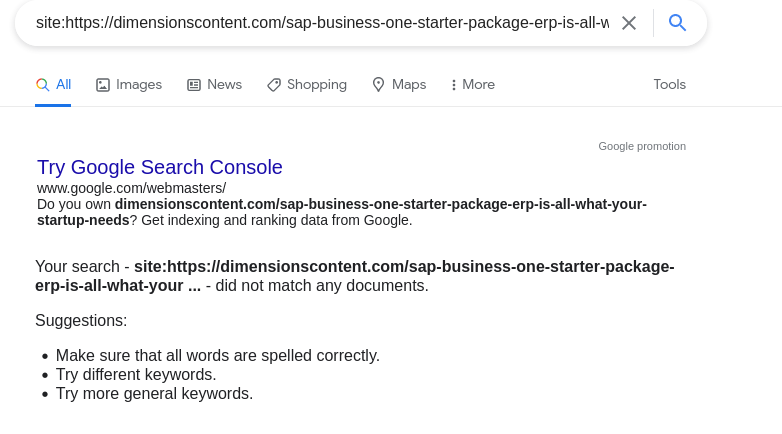
This means that the page is indeed not indexed by Google.
Google Has Two Server Types: Document Server and Index Server
Google Search is not a monolithic system. In the background, there are many services and processes that make up the whole search infrastructure.
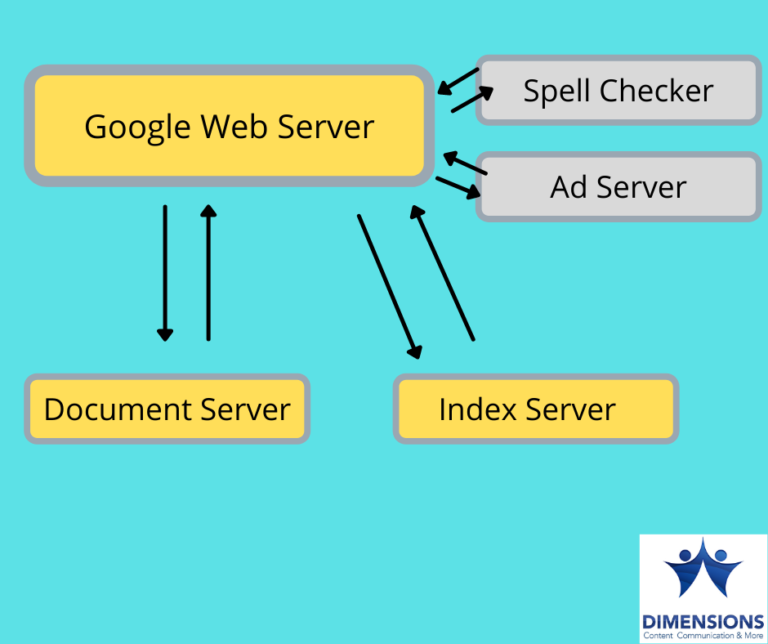
In the backend, Google has two server types: Document Server and Index Server. When you submit a content/webpage or when Google itself crawls a webpage, that content does not go directly to the index server. It remains in the Document Server.
To make Google push your content to the index server from the document server, your content needs to bring something unique to the table. If it is the regurgitation of an existing document, Google will find your content not so useful. Why? Because, all the information is already there on Google: Your content isn’t saying anything new. (Source: http://books.gigatux.nl/mirror/googlepedia/ch01lev1sec2.html)
Why Does Google Refuse To Index a Web Page Even After Crawling It?
When you see that a webpage of your website has been crawled by Google but not indexed, your natural reaction is – “Why? Just Why?” The fact that Googlebot can crawl the page indicates that there is technically nothing wrong with the webpage-
If technical errors can be ruled out, then what’s the reason behind this error? There are two major content quality related issues that can result in ‘crawled currently indexed’ error. These are-
- Paraphrased content related issue
- Thin content related issue
Let’s explain in detail.
Google Refuses To Index Paraphrased Content: One of The Most Common Causes of Crawled Currently Not Indexed Issue
Paraphrased content is technically not plagiarized content. However, you and I both know that it actually IS a kind of plagiarism. As a result if you use paraphrasing software like Quillbot to spin existing content, Google won’t thank you for that. Google’s algorithm is smart enough to detect which content is original and which content is just paraphrased from some other source.
Let us give you a hands-on example. We recently asked a freelance writer to write content for us. The topic was the Sap Starter package. The writer submitted the article within a day. We really liked the content. It was smartly written. Here’s the link to it – http://dimensionscontent.com/sap-business-one-starter-package-erp-is-all-what-your-startup-needs/ (We have made the blog post private. You have to log in to view it.)
Before publishing the article, we did a plagiarism check and the software reported that the article was original. However, little did we know that the software only checks for literal plagiarism. Today, unscrupulous people have upped their game. They don’t plagiarize, they paraphrase. So traditional plagiarism software would detect nothing. However, plagiarism software that employ AI and ML – like Copyleaks– will show that this blog is actually paraphrased from an article on Seidor.
Google can detect such spun content easily and as such it deems that these kinds of content have no value. Hence, even though it can crawl it, it won’t push the article to the Index Server.
- Are You Using AI Bots To Write Articles?
- Is your content provider just paraphrasing content? (Check the content using PAID plagiarism tools like CopyLeaks. The free ones don’t scan deeply)
If you answered either of these two questions in ‘yes’ then that’s the reason behind coverage crawled currently not indexed issue.
Thin Content: The Second Reason Behind Crawled Currently Not Indexed Issue
Now apart from the quality or plagiarism issue, we also need to focus on the thin content issue. Typically, a web page should have an average of 300 words to be considered useful by Google. Think about it, a page that has few words can’t really be useful to users. So Google chooses not to index such pages.
We can give you a hands on example in this case as well. Look at this web page of ours – http://dimensionscontent.com/tableau-technical-content/ . We created this page as a landing page. As you know, landing pages don’t contain too many words. The same is the case for our page as well. As a result, Google has not indexed it.
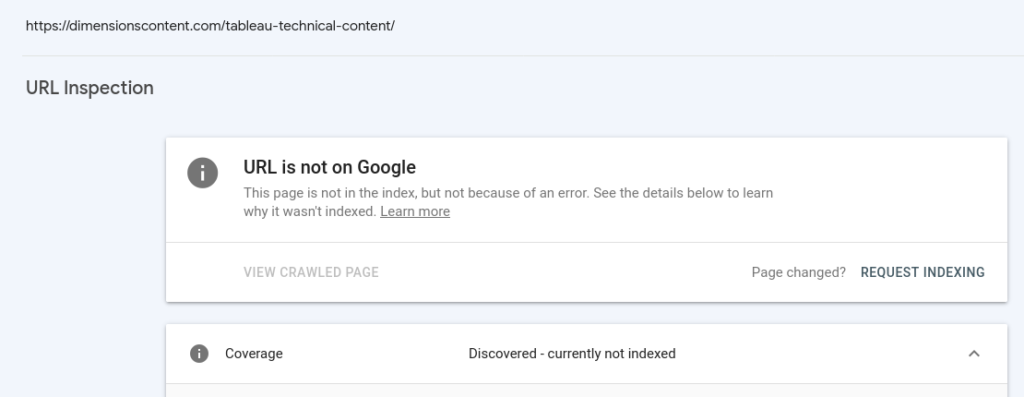
The situation is more critical in this case, because instead of the ‘Crawled, currently not indexed’ error, Google is showing ‘Discovered, Currently Not Indexed’ error even though the page is not blocked by any Robots.txt scheme. This means that Google considers the page of so little value that it has not even taken the initiative of crawling the page.
How To Solve The Crawled Currently Not Indexed Issue?
It’s easy, upload quality content and Google will have no reason to not index it. If you are outsourcing your task of content writing, make sure to tell the writer not to spin existing content using any paraphrasing software. Also, create web pages that have at least 300 to 500 words so that they are not flagged as thin content.
If you want a summerised version, here are the solutions to fix Google Crawled Currently Not Indexed issue –
- Stop using AI based content generation tool. They are just glorified paraphrasing tool.
- Deep scan the content that your writers (or agency) write with a PAID plagiarism tool.
- Try to fill your web page with at least 300 words to avoid the ‘thin content’ issue’ that results in crawled currently not indexed.
- Don’t regurgitate the same stuff. Try to come up with original ideas (even if the topic is over used). As yourself, why would Google index your content? What new thing is there that is not already on Google?
At Dimensions Content Writing Services, we pride ourselves in being able to provide strictly original content. We check each of our content to make sure that it is TRULY original.




